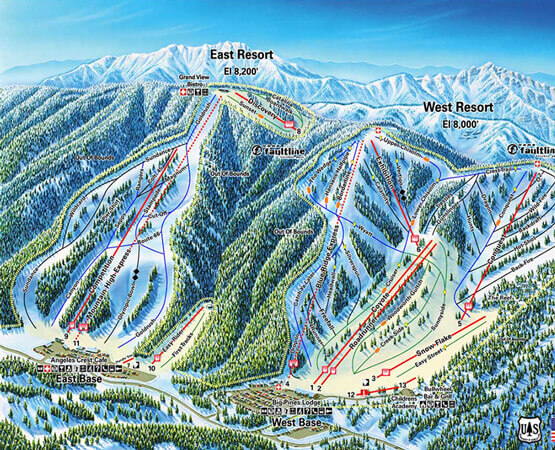
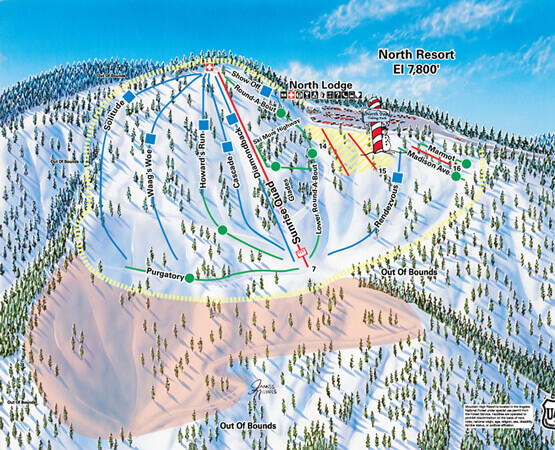
Ski and Snowboard Rentals
Welcome to McGrath’s Ski Rentals! We are a winter and snow sport rental shop in Southern California offering ski and snowboard rentals, accessories, services, gear, equipment, and more. On our site you will find our ski rental prices, snowboard rental prices, apparel rental prices, additional items we sell and serve, information about the resort, and so much more. Hit the slopes with top-quality equipment for a safe and fun time during your stay. We carry equipment from beginner to advanced. Whether you need every piece of equipment possible or just a few items, we have you covered. Rent from top-rated brands on all equipment and accessory pieces. At McGrath’s Ski Rentals, we make ski and snowboard rentals that easy!